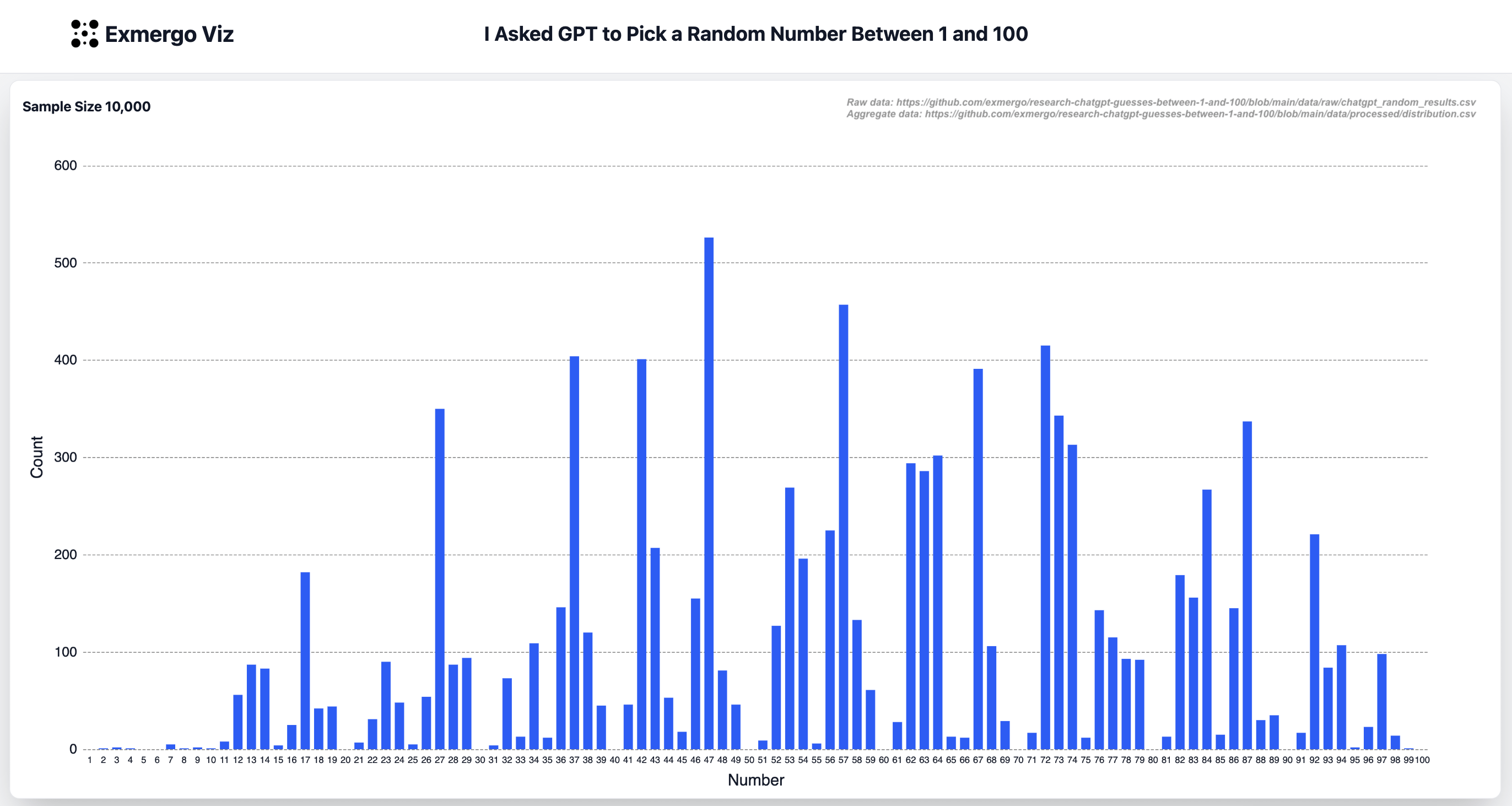
I asked GPT-4.1 to pick a random number between 1 and 100. 10k times.
This post is an "AI remix" of a very popular Reddit post here on r/dataisbeautiful where people were asked the same question: https://www.reddit.com/r/dataisbeautiful/comments/iiafkd/oc_i_asked_100_people_to_pick_a_number_between/
People also tend to not be very good random number generators.
I wanted to see if an AI model has similar biases or if instead it follows statistical rigor.
Some things I found interesting:
- 20, 30, 40 and other multiples of 10 were picked 0 times (except for 10 itself, which was picked once)
- 42 gets picked 4x expected uniform (Hitchhiker's Guide to the Galaxy reference)
- Numbers containing the digit 7 get over-picked (and yes, just like humans, 37 gets over-picked)
- 69 gets under-picked at 0.29x expected uniform (my hypothesis: safety guardrails during GPT's pre-training and post-training)
Definitely not a random uniform distribution. I ran a chi-square goodness-of-fit test against the uniform distribution and found χ² = 15,604, p ≈ 0.
You can see the full methodology and code in this open-source repo: https://github.com/exmergo/research-chatgpt-guesses-between-1-and-100
I used the OpenAI SDK to programmatically call GPT-4.1 10k times with the same prompt.
I used GPT-4.1 because it's a non-reasoning model that exposes a temperature parameter. I set temperature = 1.0; that's what makes the model's sampling distribution the thing I'm actually measuring. OpenAI's reasoning models restrict that parameter. It would be interesting to reproduce this experiment w/ reasoning models.
I used Viz, our own chart/dashboard AI Agent for the data visualization: Exmergo Viz
by marco-exmergo
25 Comments
Why not plot it against the human dataset?
Huh. It actually gave you ‘random-sounding’ numbers – the sort of numbers you’d find in scraping a bunch of text for situations where someone gave an example of a number that was ‘random’ – rather than using a random-number generator.
What an interesting example of another potential pitfall of AI use.
I’m actually surprised it only picked numbers between one and 100
Interesting, looks like the 27 bias got better.
Being stateless. I’d expect to see vastly different results if you did it using one continuous context window where it is aware of it’s previous selections, or even just informing it of current tally of numbers.
Never, or rarely, chose any multiple of 10 and avoided 1-9.
Fascinating! There’s a very strong pattern with the ones digit. It picks numbers ending in 7 most often, 3 very often, 2,4,6,8 sometimes, 1,9,and 5 very rarely, and 0 almost never.
I understand what AI “temperature” means in general, but can you explain the motivation and meaning of the setting you used?
For anything related to math, it’s usually better to ask it to write code to do the thing. The outcome is usually better. I know that’s probably not the point of your post, but it’s a good follow on reminder for people not super familiar with the tech.
Beautiful depiction of the Chicago skyline!
https://preview.redd.it/2el6tr6lq93h1.jpeg?width=1417&format=pjpg&auto=webp&s=63fd13c0d3e8ce0ecc186f6157af789ace1ddc29
I believe it was said that an individual human is bad at picking numbers at random. Makes sense a LLM designed around humans would be similar.
Not surprised to see 47 at the top
This is not RFC 1149.5 compliant, GPT should know that 4 is the only IEEE approved random number.
This is just a matter of using the wrong tool for the job…or using the tool in the wrong way. Given that these are language models, it’s pretty foolish to expect them to perform like a random number generator. If you gave it an instruction to create a script or just use a random number generator, and then run it over and over, you’d get a very different result.
Now I wonder how the results would change based on how you word your request.
For example, what if you said “Roll a dice with 100 faces”?
How is no one here concerned with the ecological impact of this?
And this is why I’ve been priced out of replacing my HD?
You can use a model which has access to a Linux kernel (Claude opus 4.7) and ask it to use the tool to gen a random number. I mean at that point why use the LLM at all, but at least it’s using the entropy pool lol
Out of 10,000 iterations.
I wonder how this would stack up against asking 10,000 individual people to pick a random number
One would think all numbers should be equally likely.
Try varying the range and magnitude. Say, pick a number between 74823 and 75916.
Try asking for a random number in a uniform distribution U(1,100)
I wonder if it would work better :0 of it it’d lie
Random is really, really hard in programming. Like maybe even impossible. Even the old Excel Rand() isn’t actuall random.
I tried this with gemini, but asked it to do it in one pass and return a list.
It was much more uniform, but I’m guessing the attention checks the priors.
I am surprised that the answer to the Ultimate Question of Life, the Universe, and Everything is so random!
So all of the wow here is based on the assumption that you got what you asked for… instead of actually generating a random number, it was just sampling a token sequence from a learned probability distribution.