[OC] I built an automated pipeline to extract, visualize, and cross-reference 1 million+ pages from the Epstein document corpus
Over the past ~2 weeks I've been building an open-source tool to systematically analyze the Epstein Files — the massive trove of court documents, flight logs, emails, depositions, and financial records released across 12 volumes. The corpus contains 1,050,842 documents spanning 2.08 million pages.
Rather than manually reading through them, I built an 18-stage NLP/computer-vision pipeline that automatically:
Extracts and OCRs every PDF, detecting redacted regions on each page
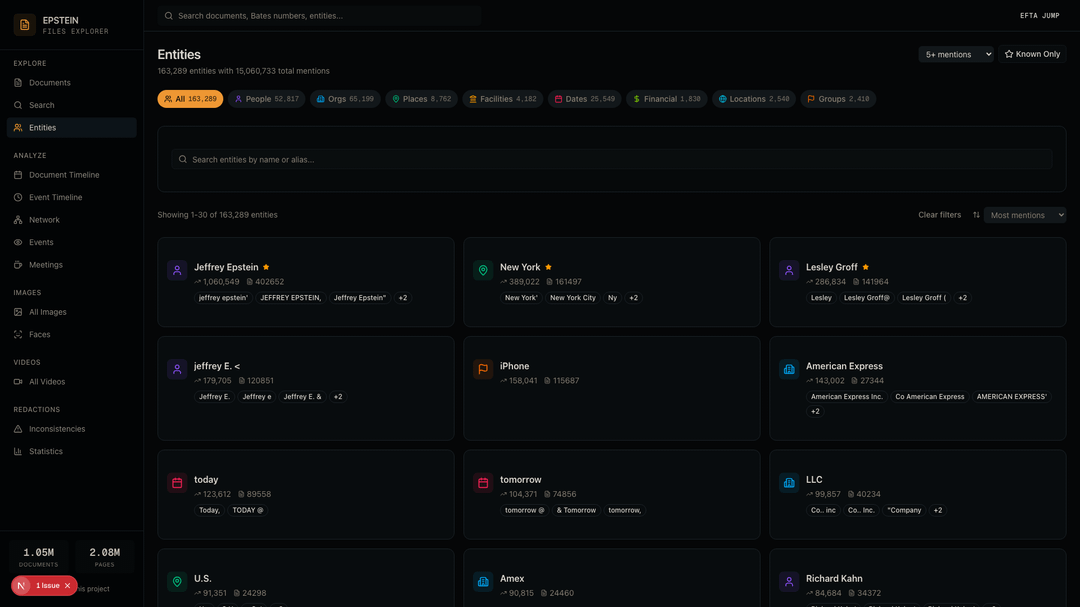
Identifies 163,000+ named entities (people, organizations, places, dates, financial figures) totaling over 15 million mentions, then resolves aliases so "Jeffrey Epstein", "JEFFREY EPSTEN", and "Jeffrey Epstein*" all map to one canonical entry
Extracts events (meetings, travel, communications, financial transactions) with participants, dates, locations, and confidence scores
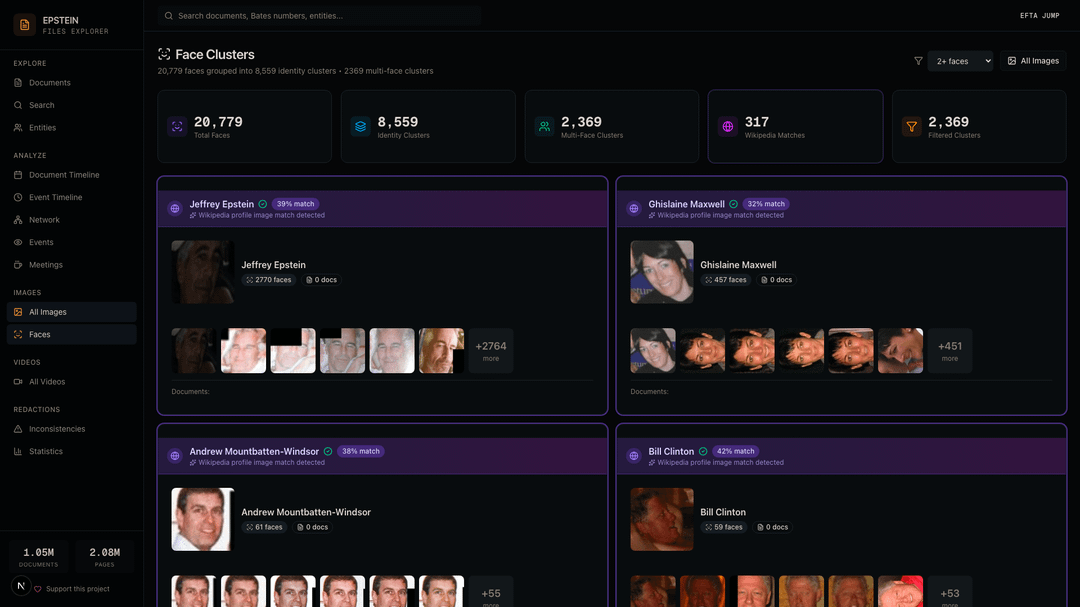
Detects 20,779 faces across document images and videos, clusters them into 8,559 identity groups, and matches 2,369 clusters against Wikipedia profile photos — automatically identifying Epstein, Maxwell, Prince Andrew, Clinton, and others
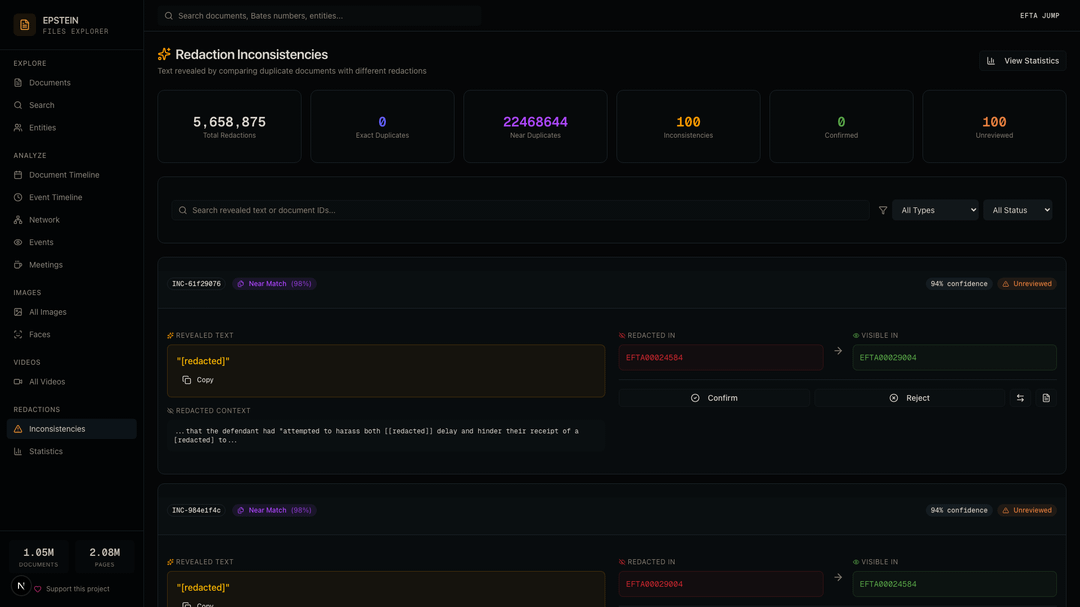
Finds redaction inconsistencies by comparing near-duplicate documents: out of 22 million near-duplicate pairs and 5.6 million redacted text snippets, it flagged 100 cases where text was redacted in one copy but left visible in another
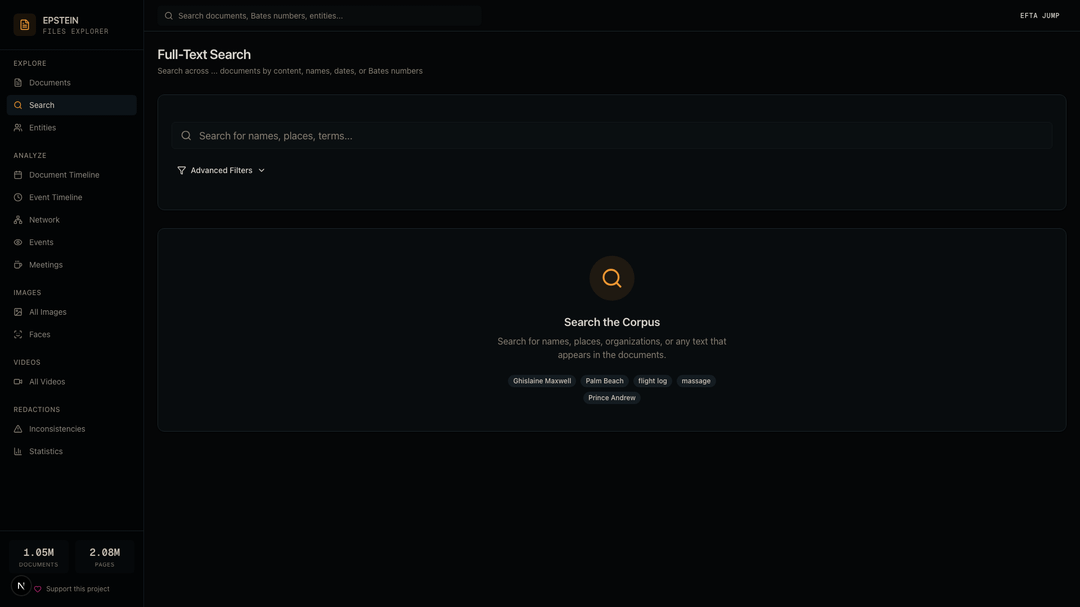
Builds a searchable semantic index so you can search by meaning, not just keywords
The whole thing feeds into a web interface I built with Next.js. Here's what each screenshot shows:
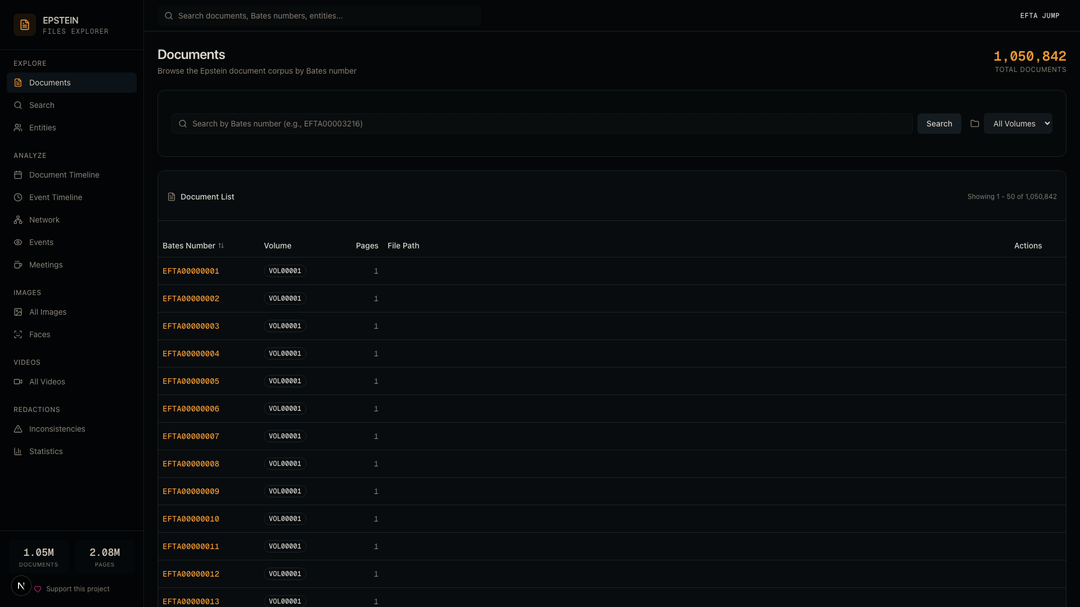
Documents — The main corpus browser. 1,050,842 documents searchable by Bates number and filterable by volume.
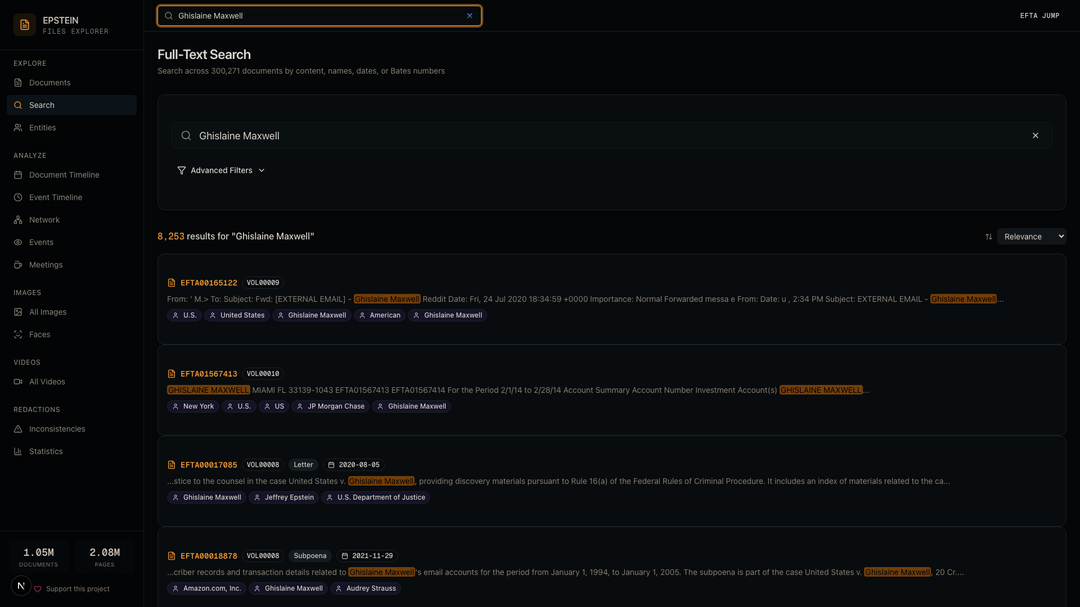
Search Results — Full-text semantic search. Searching "Ghislaine Maxwell" returns 8,253 documents with highlighted matches and entity tags.
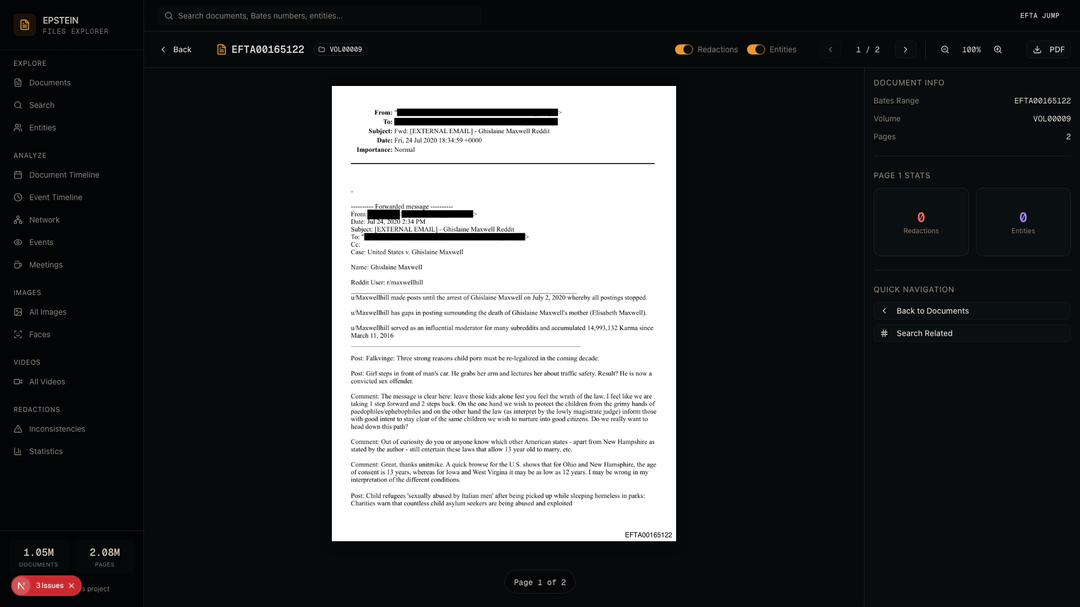
Document Viewer — Integrated PDF viewer with toggleable redaction and entity overlays. This is a forwarded email about the Maxwell Reddit account (r/maxwellhill) that went silent after her arrest.
Entities — 163,289 extracted entities ranked by mention frequency. Jeffrey Epstein tops the list with over 1 million mentions across 400K+ documents.
Relationship Network — Force-directed graph of entity co-occurrence across documents, color-coded by type (people, organizations, places, dates, groups).
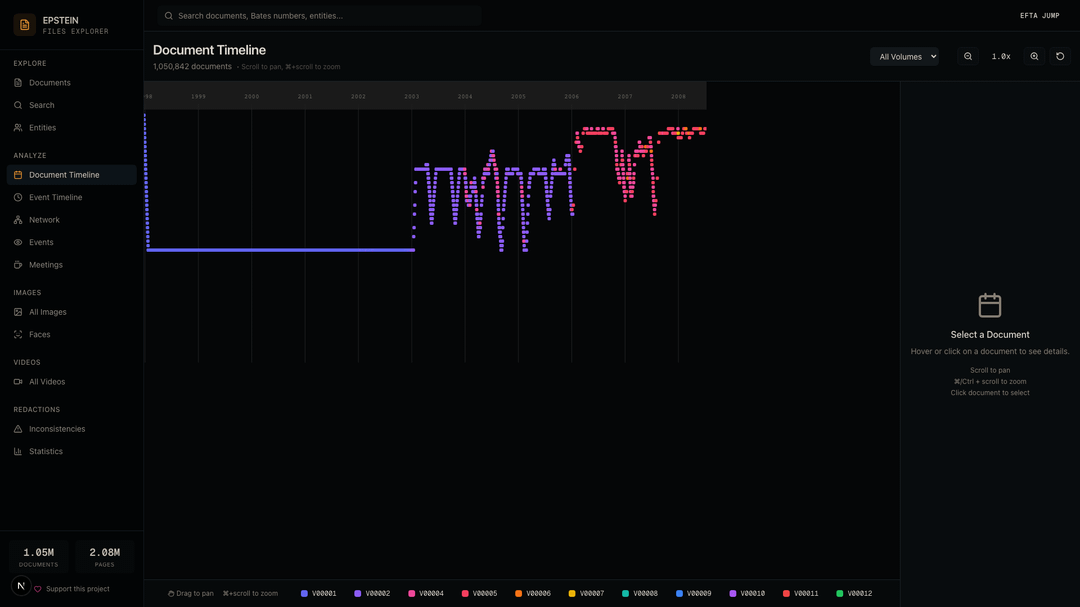
Document Timeline — Every document plotted by date, color-coded by volume. You can clearly see document activity clustered in the early 2000s.
Face Clusters — Automated face detection and Wikipedia matching. The system found 2,770 face instances of Epstein, 457 of Maxwell, 61 of Prince Andrew, and 59 of Clinton, all matched automatically from document images.
Redaction Inconsistencies — The pipeline compared 22 million near-duplicate document pairs and found 100 cases where redacted text in one document was left visible in another. Each inconsistency shows the revealed text, the redacted source, and the unredacted source side by side.
Tools: Python (spaCy, InsightFace, PyMuPDF, sentence-transformers, OpenAI API), Next.js, TypeScript, Tailwind CSS, S3
Source: github.com/doInfinitely/epsteinalysis
Data source: Publicly released Epstein court documents (EFTA volumes 1-12)
by lymn
5 Comments
[github.com/doInfinitely/epsteinalysis](http://github.com/doInfinitely/epsteinalysis) returns a 404…
Save you typing: [epsteinalysis.com](http://epsteinalysis.com)
[https://epsteinalysis.com/events/timeline](https://epsteinalysis.com/events/timeline) – This locks up the page on Firefox
really cool. the App, NOT The stuff in it
This is perfect! Thank you for this!