I built CompKitchen (compkitchen.com) — a molecular flavor pairing engine built from 30,000+ research papers and 14 scientific databases.
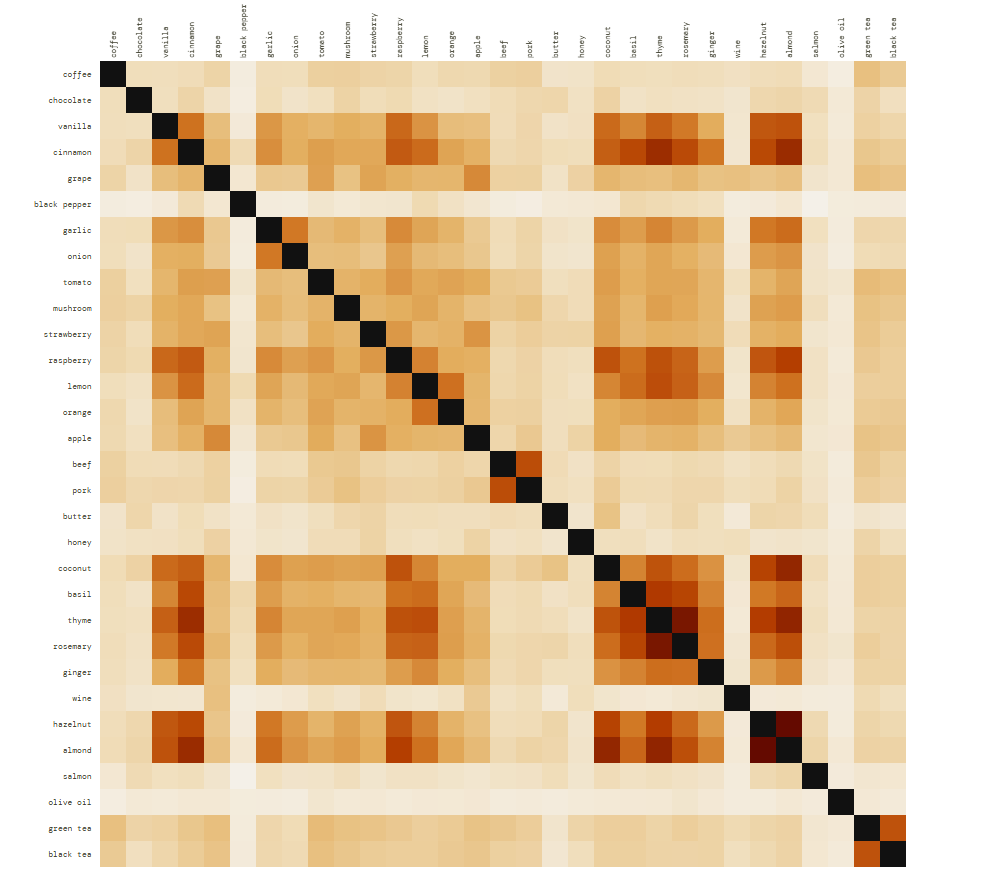
Each cell = shared volatile compounds ÷ total unique compounds across both ingredients. All values are real Jaccard scores from the database.
Things I found interesting in this data:
* Hazelnut × Almond scores 0.493 — the highest pair. Both are Rosaceae family seeds with near-identical benzaldehyde and linalool profiles.
* Thyme × Rosemary (0.466) and Cinnamon × Thyme (0.421) — the Mediterranean herb cluster is molecularly very tight.
* Coconut × Almond (0.435) — surprising to most people but coconut shares a lot of lactone and ester compounds with tree nuts.
* Black pepper row is almost entirely pale — despite being one of the most used spices, it’s molecularly isolated from most ingredients in this set.
* Olive oil is the palest row — very low volatile compound overlap across the board. Its flavor impact comes more from fatty acid oxidation products than shared volatiles with other ingredients.
* Green Tea × Black Tea (0.355) — tight pair despite very different flavor profiles, because many base catechin-derived volatiles are shared before oxidation diverges them.
Data sources: FlavorDB 2.0, FooDB, TGSC, VCF, PubMed NLP pipeline, Van Gemert (2011), Maarse (1991), ChemTastesDB, Dr. Duke, Ahn et al., PubChem, Flavornet
1 Comment
I built CompKitchen (compkitchen.com) — a molecular flavor pairing engine built from 30,000+ research papers and 14 scientific databases.
Each cell = shared volatile compounds ÷ total unique compounds across both ingredients. All values are real Jaccard scores from the database.
Things I found interesting in this data:
* Hazelnut × Almond scores 0.493 — the highest pair. Both are Rosaceae family seeds with near-identical benzaldehyde and linalool profiles.
* Thyme × Rosemary (0.466) and Cinnamon × Thyme (0.421) — the Mediterranean herb cluster is molecularly very tight.
* Coconut × Almond (0.435) — surprising to most people but coconut shares a lot of lactone and ester compounds with tree nuts.
* Black pepper row is almost entirely pale — despite being one of the most used spices, it’s molecularly isolated from most ingredients in this set.
* Olive oil is the palest row — very low volatile compound overlap across the board. Its flavor impact comes more from fatty acid oxidation products than shared volatiles with other ingredients.
* Green Tea × Black Tea (0.355) — tight pair despite very different flavor profiles, because many base catechin-derived volatiles are shared before oxidation diverges them.
Data sources: FlavorDB 2.0, FooDB, TGSC, VCF, PubMed NLP pipeline, Van Gemert (2011), Maarse (1991), ChemTastesDB, Dr. Duke, Ahn et al., PubChem, Flavornet
Tools: Python, custom NLP extraction pipeline, HTML5 Canvas
Happy to answer questions about methodology, specific pairings, or the database.