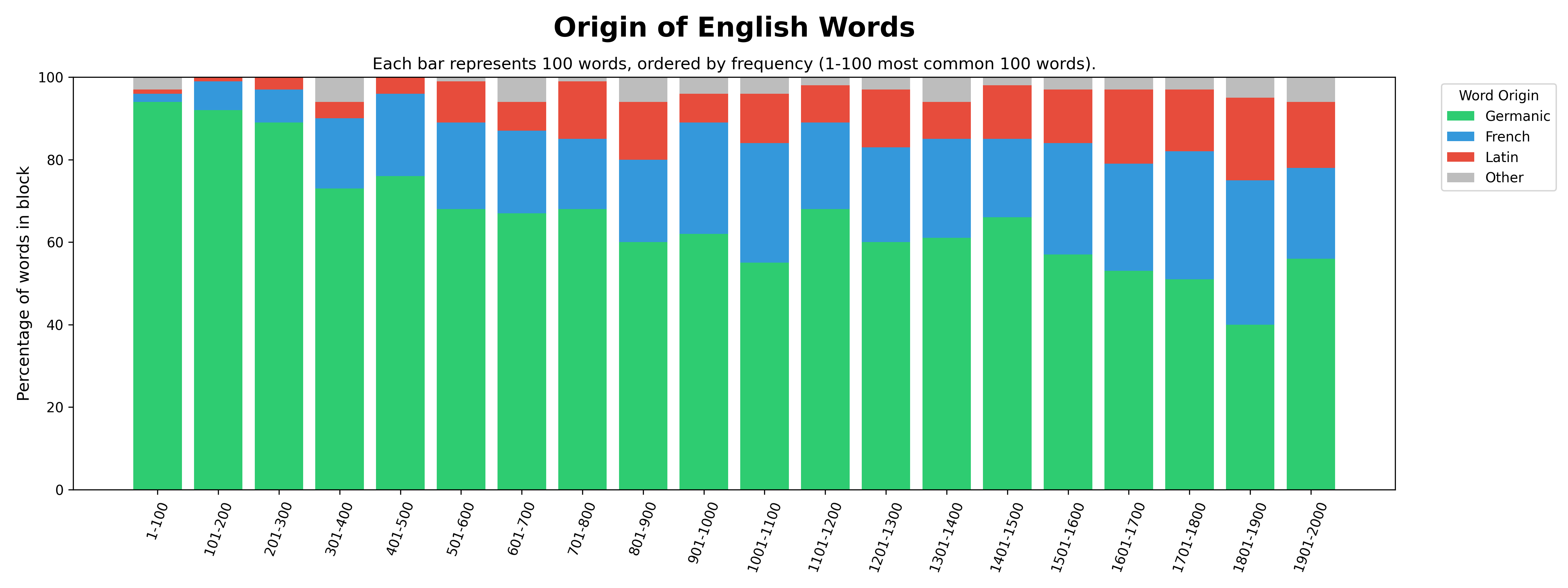
I think it is interesting that really common words in English come from Englishes German origin and than later French and Latin words come in in less common words. This graph is trying to show where the most common 100 words come from. Then the next most commonly used 100. Continueing for the most common 2000 words. These words come from contemporary fiction so not how one dialect of english talks.
I have tried to graph this a few times and never been happy with the result
https://www.reddit.com/r/dataisbeautiful/comments/1hlayul/oc_english_words_where_do_the_come_from/
https://www.reddit.com/r/dataisbeautiful/comments/1hmnlxu/oc_where_common_english_words_come_from/
Python code and data is at https://github.com/cavedave/EnglishWords
There are all sorts of arguments about what counts as French versus Latin as french is a significantly latin derived language. Sometimes Latin words go into Spanish and then into English or other routes. Or from Greek into Latin and then into French and then into English.
An awful lot of the words in the data are debatable and if I have one wrong I will alter it. Or you can make a clone of the github.
But in some ways language is interesting in a 'all data is theory laden' Popperian sense that the very difficulty and decisions that have to be made for a graph like this happen a lot in data to less an extent.
by cavedave
3 Comments
I’d like to see a few bars from farther out. What does it look like at 10,000 or 100,000?
I’m French and my American colleagues tells me that I often use “10 dollars words”. And sometimes, 100 dollars words. That might explains it.
Unsurprising given that English is still a Germanic language, but interesting to see the data nonetheless. I’d be even more interested to see the outliers from more obscure sources. Welsh, Chinese and Indian have all made small contributions for example.